Flow sketching and traffic correlation attack
 Recent paper reading on traffic correlation attack and flow skeching, last update (2017.3.13)
Recent paper reading on traffic correlation attack and flow skeching, last update (2017.3.13)
1. 本文概要
Paper Reading notes on:
- Online Sketching of Network Flows for Real-Time Stepping-Stone Detection[1]
- Traffic confirmation attacks despite noise[2]
- Tracking encrypted VoIP calls via robust hashing of network flow[3]
2. Background
2.1 Stepping stone
直接翻译过来叫做垫脚石攻击,感觉有点奇怪。
垫脚石(Stepping stone): The intermediate hosts used for traffic laundering are known as stepping stones. 垫脚石就是攻击者利用一系列中间主机作为跳板,为了掩盖攻击者的真实身份和位置的一种攻击方式。
垫脚石攻击的检测:在网络设备中记录流的一些信息。然后根据关联算法,能够找到真正的攻击源。传统的垫脚石攻击检测算法记录流的一些基本特征,例如流的包数量,包间隔时间等等。 但是传统的垫脚石攻击检测对丢包,噪声和网络环境变化并不能很好适用。(However, they provide very limited or no resistance to some of the aforementioned timing perturbations, especially packet drops/retransmissions and chaff.)而且传统的垫脚石攻击检测算法相对于本文的算法保存了更多的信息,不利于大量流量的数据处理,因此流量关联算法的时间复杂度比较高 O(m*n), m是出去方向的流个数,n是进入方向的流量个数。
2.2切比雪夫不等式(Chebyshev inequality)
若随机变量X的数学期望、方差分别为E(X)及D(X),则对任何\(\epsilon >0\),成立
几何解释及意义详见: https://www.zhihu.com/question/27821324
2.3 相关工作
本文所提出的技术与鲁棒散列方案(Robust Hashing)类似。 它们都通过短序列(鲁棒散列)表示输入信号,这个序列的性质可以让其抵抗输入上的小扰动。 在多媒体信号处理的运用中,即便原始信号收到干扰或者变化(例如压缩,次滤波等),鲁棒散列函数仍然能够识别和认证多媒体内容。
3.流量Sketch计算和表示方法
实时的流量关联:在网络边界上,记录出入的active流的信息。active流在文章中设置的是60s的超时时间。如果在时刻\(t\),出去方向的第\(i\)号流\(E_i (t)\),和进入方向的第\(j\)号流\(I_j (t)\), 满足\(Diff_t(E_i (t),I_j (t)) < \epsilon \) 那么这两个流就被关联起来了。 Diff方法在文章中采用的汉明距离,然后两个流的sketches都是用binary的形式进行保存的。 采用新的表示方法,节约了保存空间,提高了计算效率。
一个流的Sketch是如何进行计算的呢?这里的high-level idea是将流量的packet-timing 特征进行线性变换,如果两个输入向量相似那么新产生的这两个向量也会相似。 具体做法是将一个流的传输分为k个time slots,每个time slot (t) 统计传输的包的数量 \(V_F(t)\), 然后每个time slot (t)对应一个随机映射函数(也可以是随机数)。 再计算k个累计的包传输数量和 \(C_F(i)\) (i=1,2,…,k), 最后根据\(C_F(i)\) 的符号进行编码(大于0的编码为1,小于等于0的编码为0),最终形成一个长度为k的0,1序列。
一个例子:
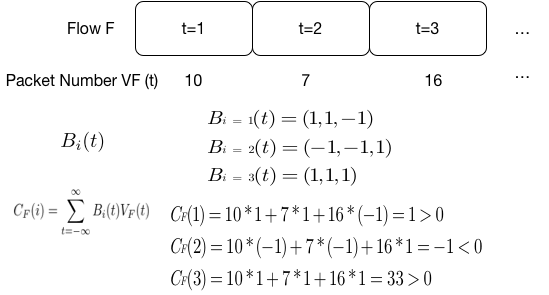
最后根据符号函数得到该流的sketch 为 101, 如何后续还有数据包进出的话,那么就在101的基础之上向后同理进行计算,如上图省略号所示。
3.1流量Sketch的基本性质
假设两个Flow,F1和F2相似,那么F1和F2的最后sketch也应相似。但是现实中基本不存在两个流完全一样,那么这两流的sketches的比特错误的概率大小\(P_{e}(F1,F2)\) 应该较低才满足相似的规定。比特错误的引入归根结底是因为\(V_F(t)\),那么我们定义F1,F2包数量之间的不同为:
带入上式(\(C_F(i)\)的那个)
那么有
| 要使得两个bit异号,那么上述\(C_F2(i)\), \(C_F1(i)\)得异号。 那么异号的条件就是 \( | \sum B_{i}(t) \varepsilon (t) | > C_{F1}(i)\) 以及 \(\sum B_i(t) \epsilon (t)\) 和 \(C_F1(i)\) |
最后根据切比雪夫不等式(省略一些步骤)得到一个重要不等式:
| 上式表明,F1, F2 的包数量之间的不同越大(分子),那么比特错误的概率就越高。 反之,如果 \( | C_F1(i) | \)的个数增多(即线性变换的随机基向量越多),那么表明这两个流的sketches 比特错误的概率越低,从而一定程度上降低了sketches对噪声的敏感程度。 |
注明:web版latex公式上下标有点问题,文中公式有可能存在错误.
4.流量Sketch搜索
本质上文中采用的是空间换时间的方法,将原来的O(mn)算法,降低到 \(O(n +\sqrt{mn})\), 具体思路还是比较好理解的。这里不再赘述。
5. 流量关联攻击
流量关联攻击可以帮助我们找到两个相似的流。论文[2][3]创新地将[1]的方法运用到追踪溯源中,其具体做法如下图所示。
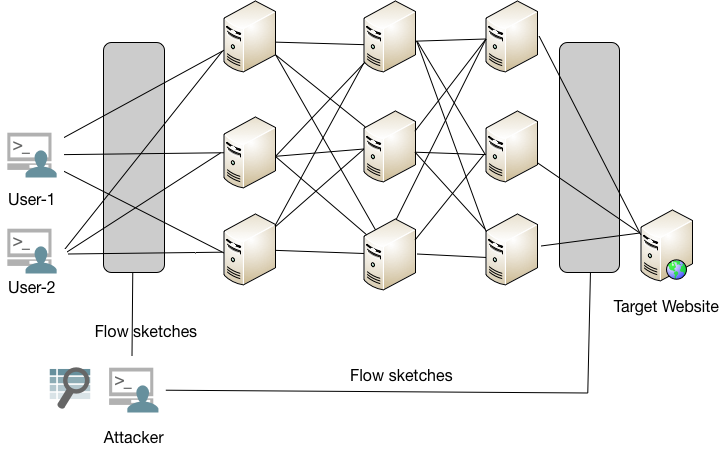
攻击者是passive listener,在入口和出口处对流量进行Hash(其实和[1]中的流量sketches很类似,有些小不同后面会介绍),然后找到哪个user访问了target website,从而达到溯源目的。
如何计算流的binary hash呢?
[3]的算法如下:

算法[3]和[2]的不同之处就在于,[3]的B增量是以字节大小表示的,[2]是以包的个数表示的,由于报文填充机制,所以[2]没有利用包的大小信息。
[2]的算法如下:

- Line 1: 初始化binary hash 向量
- Line 2: 为每个time window 提取该窗口的包数量
- Line 3: 对于每个窗口进行计算
- Line 4~6: 对于第一个窗口,计算稍微有些不同
- Line 7~10: 对于后续窗口如何进行Hash值计算,Line 8计算和前一个窗口的包数量差,Line 9, 用增量update H。那个加号其实就是向量加法,后面的中括号其实就是随机向量,这里的m应该和H的长度一样才行,也就是说随机数的个数要和binary hash长度一样。
- Line 11: 符号函数,如果H对应的bit位置的值大于0则编码为1, 如果小于等于0则编码为0。感觉应该可以放到for循环外。
问题:如何得到窗口个数N? Answer: 对于每个flow,N都是一样的。 N is decided on prior to computation,如果包数量比窗口数量还少,那么丢弃该流。
Refs
[1] Coskun B, Memon N D. Online Sketching of Network Flows for Real-Time Stepping-Stone Detection[C]//ACSAC. 2009: 473-483.
[2]Hayes J. traffic confirmation attacks despite noise[J]. arXiv preprint arXiv:1601.04893, 2016.
[3]Coskun B, Memon N. Tracking encrypted VoIP calls via robust hashing of network flows[C]//Acoustics Speech and Signal Processing (ICASSP), 2010 IEEE International Conference on. IEEE, 2010: 1818-1821.
Posted by 灵犀一点00 - 2017-03-10
如需转载,请注明: 本文来自 Jasonzhuo's Blog