Encrypted Traffic identification
 2015加密流量检测论文阅读笔记,持续更新(last update 2015.11.01)
2015加密流量检测论文阅读笔记,持续更新(last update 2015.11.01)
目前还有效的加密流量识别方法
- 基于端口号的,局限性很大但某些场景仍然有效。
- 基于内容签名的。有些加密协议有固定特殊的内容特征。
- 基于流特征的。加密协议在进行密钥协商时具有特殊过程。
- 基于主机行为的。从主机行为来看加密协议的建立过程,局限性仍然很大。
论文[1]作者的方法
上述方法的局限性较大。论文[1]中作者采用了随机度测试的方法来对加密流量进行识别。首先作者利用了\(l_{1}-norm\) regularized 逻辑斯特回归来选择sparse特征(特征中有很多0值),然后利用了ELM来对加密流量进行识别,选择ELM的原因是其具有更好的识别效果和更快的识别速度。
作者在论文[1]中利用随机度测试方法获取了188维度的特征,然后利用一范数正则化方法对特征进行降维。最后再利用ELM学习算法,对加密流量进行识别。
识别效果和支持向量数据描述(support vector data description)SVDD以及GMM方法进行了对比。可见作者采用了one-class分类。最后的结果是识别率大概在80%左右。
随机度测试与加密方法
如何衡量加密算法的强弱好坏呢。有一种方法就是加密密文需要通过一定的随机度测试,输出的密文需要是随机的,或者近似随机的,这样的加密效果才好。衡量随机度的参数P-value越大则随机的可能性越高。参考:知乎:如何评价一个伪随机数生成算法的优劣
下图比较形象的说明了随机数测试的问题cited from https://www.random.org/analysis/
 现在随机度测试的方法很多,如:NIST test set, DiEHARD test set等等,其中以美国国家标准与技术研究所的NIST最为著名:NIST传送门,NIST安装过程介绍
现在随机度测试的方法很多,如:NIST test set, DiEHARD test set等等,其中以美国国家标准与技术研究所的NIST最为著名:NIST传送门,NIST安装过程介绍
NIST SP800-22 测试标准包含15个测试项,每个测试项都是针对被测序列的某一特性进行检测的,如下图所示。图片引用自[2]
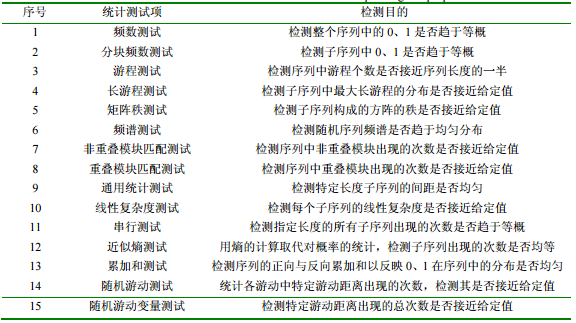
NIST15种随机性测试简介[8]
1.频率测试(Monobit Test)
检验目的: 测试0和1在整个序列中所占的比例。如果0和1在整个序列中出现的频率都接近0.5,那么就是说在整个序列中0和1出现的概率基本一致,因此序列是随机的。
检验过程:
1.将序列中的0映射为“+1”,0映射为“-1”,然后对整个序列求和得到\(S_n\)
2.计算统计检验量\(S_{obs}=\frac{|S_n|}{\sqrt{n}}\),其中\(n\) 为序列长度
3.计算P-value:
其中erfc(Complementary error function)定义为:
数学原理:当测试次数充分多时,二项分布B(n,p)逼近正态分布N(np,npq),\(S_n\)又叫做规范和,它被正则化后就服从正态分布了。 做假设检验: 如果Pvalue>0.01那么就说该序列为随机序列,反之则不是。如果Pvalue的值太小,那么就表明Sobs或者\(S_n\)较大引起的,表明序列中要么0特别多,要么1特别多,这样就不是随机的。
2.分块频数测试
检验目的:主要是看M位的字块中“1”出现的次数,如果比例接近为M/2那么就是随机的。当M=1时,变化为频数测试。
测试过程:
- 将序列分为长度为M的N块,因此n=MN
- 由于这N个相互独立的随机序列均服从标准正态分布,这N个服从标准正态分布随机变量的平方和,构成新的随机变量,服从卡方分布,其自由度为N
- 利用卡方分布的假设检验过程,判断原序列是否是随机的。
该测试也是看Pvalue的值,如果Pvalue>0.01那么就说该序列为随机序列,反之则不是。
3.游程测试
检验目的: 游程是指一个没有间断的相同数序列。长度为k的游程包括k个相同单位。游程测试的目的是判断不同长度的“1”游程数目,以及“0”游程的数目是否跟理想的随机序列期望一致。具体来讲,就是看这样的“0”“1”子块之间震荡是否太快或者太慢。
测试过程:
- 计算检验前输入序列中“1”的出现频率
- 判断游程测试的前提条件是否满足,如果不满足则退出测试。
- 计算检验统计量Vn(obs), 其中\(V_{obs}\),0到1或者1到0的变化次数和。
- 计算Pvalue的值
数学原理:当测试次数充分多时,二项分布B(n,p)逼近正态分布N(np,npq),\(V_{obs}\)又叫做规范和,它被正则化后就服从正态分布了,如果Vn(obs)的值很大,则表明震荡很快,反之表明震荡很慢。
4.块内最长游程检验
检验目的: 该检验主要是看长度为M-bits的字块长度中最长的“1”游程。检验目的是判断待检序列中的最长“1”游程长度是否同随机序列一致。
测试过程:
- 将序列分作长度为M-bit子块,程序里面规定了3种不同的字块长度,分别为8,128,10000,n= M*N
- 将各个字块中的最长“1”游程频率列表
- 计算卡方分布的P值
5.二元矩阵秩检验
检验目的: 该检验主要是看整个序列的分离子矩阵的秩。目的是核对源序列中固定长度子链间的线性依赖关系。
6.离散傅里叶变换检验
检验目的:本检验主要是看对序列进行分步傅里叶变换后的峰值高度。目的是探测待检验信号的周期性,以此揭示其与相应的随机信号之间的偏差程度。做法是观察超过 95%阈值的峰值数目与低于5%峰值的数目是否有显著不同。
未完待续。。。to be continued
特征提取与选择
作者在文中利用NIST测试套件,通过不同的参数调节产生不同的测试小项,总共提取了188维度的特征。然后作者利用稀疏特征提取(Sparse Feature selection)。并在逻辑斯特回归中加入了1范数罚参。
ELM 简介
传统的SVM和神经网络需要人们进行干预,学习速度较慢,学习泛化能力也比较差。极限学习机具有较快的学习速度以及良好的泛化性能。然而,它的性能还可以得到很大提高,主要基于两个原因[3]:(1)极限学习机网络中的隐层节点可以减少;(2)网络参数不必每次都调节。
我感觉ELM和传统神经网络学习过程中最大的区别就在于如何求解最小化损失函数。传统的神经网络在学习过程中,学习算法需要在迭代过程中调整所有参赛。而在ELM算法中,直接通过求H的广义逆矩阵,输出权重\(\beta\)就可以被确定。
为啥不需要调节参数了呢,原来Huang 已经证明了具有随机制定的输入权值、隐层阈值和非零激活函数的单隐层前馈神经网络可以普遍近似任何具有紧凑输入集的连续函数。由此可以看出,输入权值和隐层阈值可以不必调节[3]。
另外可以参考ELM算法简介
还有ELM算法基础
论文[6]阅读笔记
作者在文章中介绍了加密流量识别的基本情况,强调了最近的进展和未来的发展可能会遇到的挑战。文章中指出,加密流量类型主要集中在:SSH,VPN,SSL,加密P2P,加密VoIP,匿名网络流量。
仅仅粗粒度区分加密和非加密流量是远远不够的,现实世界迫切需要的是从加密中获取应用层类型。这显然是相当复杂的工作,许多方法的综合运用才可能达到该目的。另外,协议混淆(traffic obfuscation)和流量变形(traffic morph)可以达到绕过基于机器学习的统计分类的效果,同样是未来的挑战之一。论文没有开放下载,只读了其中能看到的部分,就已经读到的内容来看,感觉文章综述很一般。
SSL/TLS应用层流量识别
1.论文[4]阅读笔记
在未加密情况下识别应用层类型是比较成熟的,然而在加密情况下识别就相对困难许多。
作者在文章中提出了使用随机指纹(stochastic fingerprints)来识别SSL/TLS会话过程中的应用类型。指纹是基于一阶马尔可夫链的,然后马尔可夫链的参数是通过训练集合学习得到的。由于参数的不同性,该方法能有效的检测出应用层类型,以及异常的SSL会话过程。
该方法和一些其他的SSL指纹识别方法比较类似,也是利用SSL/TLS握手过程中的头部信息。不同之处在于作者利用的是基于马尔可夫链随机指纹,将不同应用层类型的SSL/TLS握手过程的状态转移形成带有不同参数的马尔科夫状态转移链。作者在论文中对12项常用的SSL类型进行了建模:例如PayPal,Twitter,Skype等等。
2.论文[5]阅读笔记
传统的基于载荷的和机器学习的方法给系统造成的负载较大。作者提出了利用基于指纹和统计分析的混合方法来解决该问题。作者首先使用指纹来检测出SSL/TLS,然后再利用统计分析来找出确定的应用层类型。实验结果表明,该方法能够99%识别SSL/TLS流量,并达到F-score为94.52%的应用层识别效果。
作者识别SSL/TLS流量的方法主要还是基于流量关键字段特征,这点和普通方法没区别。作者将SSL/TLS流量识别出来之后,又用了贝叶斯方法来对加密流的特征进行学习,统计特征包括:平均包长度,最大最小包长度,平均包到达间隔时间,流持续时间,流所包括的包数量。总体感觉创新不是很大。
3.论文[7]阅读笔记
论文作者根据加密会话数据内容中常见字符和非常见字符出现概率相近,非加密会话常见字符出现次数多,而非常见字符出现次数少的现象,设计了一个根据信息熵的加密会话识别方法。作者认为,不同加密会话信息熵的统计结果服从正态分布,加密会话的信息熵取值范围由均值\(\mu\)和方差\(\sigma\)决定。作者提出了字符信息熵值H,只要在\(H\in [\mu-2\sigma, \mu+2\sigma] \),则认为是加密会话。字符信息熵值和普通信息熵值在计算形式上只有一个分母上的差别,和我原来看过的一篇论文比较类似。另外,作者并没有说明为什么取2倍的置信域而不是3倍置信域,均值和方差的设置是经过大量实验取的经验数据,而没有较为科学的取值依据。论文并未有很好地说明为什么在拥塞网络环境下,识别准确率会降低的原因。
参考文献
[1]Meng J, Yang L, Zhou Y, et al. Encrypted Traffic Identification Based on Sparse Logistical Regression and Extreme Learning Machine[M]//Proceedings of ELM-2014 Volume 2. Springer International Publishing, 2015: 61-70.
[2]侯佳音, 萧宝瑾. 随机数测试标准与随机数发生器性能的关系[J]. 2012.
[3]王建功. 基于极限学习机的多网络学习[J]. 2010.
[4]Korczynski M, Duda A. Markov chain fingerprinting to classify encrypted traffic[C]//INFOCOM, 2014 Proceedings IEEE. IEEE, 2014: 781-789.
[5]Sun G L, Xue Y, Dong Y, et al. An novel hybrid method for effectively classifying encrypted traffic[C]//Global Telecommunications Conference (GLOBECOM 2010), 2010 IEEE. IEEE, 2010: 1-5.
[6]Cao Z, Xiong G, Zhao Y, et al. A Survey on Encrypted Traffic Classification[M]//Applications and Techniques in Information Security. Springer Berlin Heidelberg, 2014: 73-81.
[7]陈利,张利,班晓芳等.基于信息熵的加密会话检测方法[J].计算机科学,2015,42(1):142-143,174.DOI:10.11896/j.issn.1002-137X.2015.1.033.
[8]Rukhin A, Soto J, Nechvatal J, et al. A statistical test suite for random and pseudorandom number generators for cryptographic applications[R]. Booz-Allen and Hamilton Inc Mclean Va, 2001.
Written with StackEdit.
Posted by 灵犀一点00 - 2015-05-11
如需转载,请注明: 本文来自 Jasonzhuo's Blog