“On Tor DNS“
 The effect of DNS on Tor’s Anonymity 论文阅读笔记, last update (2017.3.15)
The effect of DNS on Tor’s Anonymity 论文阅读笔记, last update (2017.3.15)
我又回来了
之前在忙各种出国手续,写论文,做实验之类的事情,博客从去年8月到现在都没更新过,想想也是太烂龙了。最近翻到一本《精进:如何成为一个很厉害的人》,发现写博客还有如下功效,遂立即开始写作(以后也要坚持才行):
写博客(写作)是一种典型的知识构建活动,或者更准确的说,是一种对知识的重构活动。
在阅读时,我们对信息的输入和纳入(读论文),常常满足于从一个“浅表”的层面去理解它们。 但是在写作时,也就是进行信息输出的时候,我们必须去分析知识的“深层结构”,观察和调用知识与知识之间的深层关联,不然我们无法自如地将它们组织起来。因为一篇文章要被人读懂、要把人说服,需要缜密的思维、清晰的表达和详实的依据,这些都要求我们队知识的编码和组织达到一个相对较高的水平才行。
自己下来多理解一下才行,开始写!
作者论文的主要贡献
- 提出了一种找Tor出口节点使用的DNS服务器的方法
- 提出了名为DefecTor攻击方法,该方法属于关联攻击(correlation attack)的一种,用于溯源
- 在TorPS上分析了该新攻击方法对Tor用户造成的影响
- 提出了一种更好的衡量(evaluate)关联攻击的方法
本篇内容主要讲贡献2,后面逐步更新
Tor DNS解析过程
首先Tor的DNS都是从Tor网络中走的,这点是Tor client (web browser)预设值,目的是防止DNS外泄。因为Tor不能够代理UDP流量,所以Tor proxy将DNS request 包装进Tor CELL中。 浏览器将解析地址传给Tor client proxy, 然后Tor client 选择一个可以用的出口节点,并与其建立连接(应该是3跳连接,不是1跳连接,参考Tor spec), Tor出口节点解析后,才会与目地网站建立TCP连接,成功之后返回Relay_connected cell. 另外一种DNS解析方法是构建Relay_resolve cell, 这个不同在于没有后续的TCP连接。
Tor出口节点会根据其主机配置进行DNS解析,主机的DNS解析一般流程 参考这里:Linux DNS
作者在文章中指出:大约4成的DNS流量都去了谷歌的DNS(8.8.8.8), 第二多的就是去本地DNS服务器解析。
Defctor 攻击模型
文章中的重要假设:
- 每次网页访问只产生一个DNS请求,不考虑嵌套请求(embedded request)和 DNS caching
- 出口节点的DNS请求和正常用Tor browser 但不经过Tor 网络访问网站的DNS请求一样(不太清楚)
- 为了达到最好的关联攻击效果,用户选择的路径(出入口)被攻击者所控制。
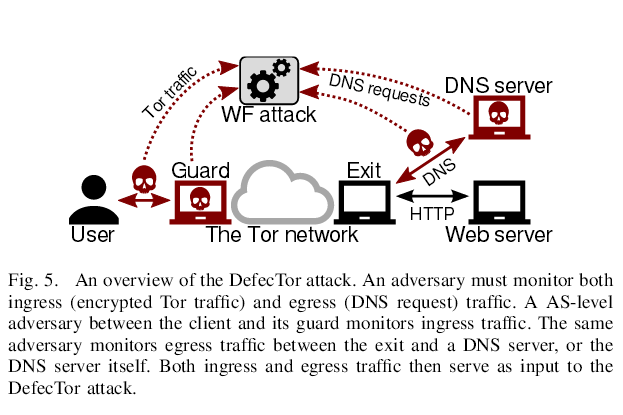
如上图,攻击者的位置有两个(需要同时满足):
1)出口节点和DNS服务器之间(或者攻击者控制了DNS服务器)
2)在用户或者Tor guard之间(或者控制了Tor guard)
关联攻击,同时对比1)和2)处的流量,达到溯源目的是这篇文章的主要思想。不同的是该文章对比的是DNS流量,传统的方法是对比TCP流量。
实验方法
作者在论文中对:1)用户使用Tor访问哪些网站,2)多久访问一次这些网站,进行了统计,3)如何对Tor出口节点的DNS缓存进行了考虑。发现了如下结论:
1)用户访问的网站服从幂律分布
2)作者实验使用的Tor出口节点大概每5分钟发出102次DNS请求(中位数),然后作者根据Tor带宽进行推测,真实网络中Tor出口节点大概每5分钟发出119.3次DNS请求(中位数),一次网站访问大概会平均造成10.3到不同域名的DNS请求,因此得出每十分钟大概可以发现23.2个不同网站。
3)Tor client 会缓存DNS请求,TTL最小为60s,最大为30分钟(目前统一为60s)。作者利用60s的滑动窗口,就可以发现所有的DNS请求,无论它是否缓存过。
作者使用的Tor浏览器来发送DNS请求,但不使流量通过Tor网络,其目的在于为了防止原来有些顶会所讨论的Tor拒绝服务情况。作者意图通过DNS来判断用户所访问的网站,实现了一个Naive classifer, 主要通过unique domains: domains that are unique to a particular website来进行关联。 作者通过对DNS请求进行特征提取(extractdns),主要提取了observed domains, TTLs and IP-addresses这三个特征。然后利用dns2site(Go脚本代码)将生成的dns list map 到 具体的 site(具体算法是利用投票进行的)。
这里总结一下,Naive classifer 主要分类依据是unique domains mapping, 作者使用的数据集是top one million alexa websites 每个主页访问5次的那个数据集。
作者另外还根据DNS请求进行了额外的特征提取,从而可以利用Tao Wang 的 KNN算法进行分类。因此在这个实验中,作者利用了Tao Wang论文中所提出的一些特征,共1225个,然后利用Wa-KNN进行权重训练,最后进行分类。 我感觉作者分了两次来做实验,一次是在出口节点搜集DNS流量,第二次是在入口节点根据Tor log信息(log incoming and outgoing cells)来搜集流量,因此入口节点处采用的是KNN,出口节点采用的是Naive classifer。
这里再总结一下,KNN算法依据的是Wang et al.,作者使用的数据集是1000个(每个100个instances)网页, 和额外的100000个网页(每个1个instance)的数据集。 验证采用的是10折交叉验证方法。
那么问题来了,作者如何是将这两个结果关联起来的呢? 作者在论文中还提到了一个叫做 hp(high precision) 的attack,这个attack应该就是起到关联作用的。 只有当hp attack成功观察到入口和出口节点有相同网站时,才进行汇报(关联),相当的simple和effective。 在这里因为Naive classifer采用的DNS mapping, 其效果能达到 94.7%的recall和98.4%的precision,因此作者有理由认为,如果我在入口节点看到了一个我检查的网页,并且我在出口处也看到了该网站,那么就有较大的可能性达到了溯源的目的。然而,作者在出口节点观察到的DNS请求并不一定来自该入口节点,有可能别的用户也在同一时间从相同出口处访问了这个网站, 这就有个概率比例问题了(攻击者能观察多少比例的出口流量?)。果然,作者后来又说: We conclude that DefecTor attacks are perfectly precise for unpopular sites(因为popular site 会有很多人访问) because it is unlikely that more than one person is browsing a monitored site within the timeframe determined by the window length. 这个感觉还是有点道理的,看读者怎么想了吧。
分析作者搜集DNS流量的实验平台框架(偏工程)
作者搜集Alexa前100万的DNS流量,无论是从数量级还是工程难度来说都是具有一定挑战的。笔者饶有兴趣的看了一下大神们的做法,将一些要点记录在这里.
Refs
[1] https://nymity.ch/tor-dns/
Posted by 灵犀一点00 - 2017-02-19
如需转载,请注明: 本文来自 Jasonzhuo's Blog